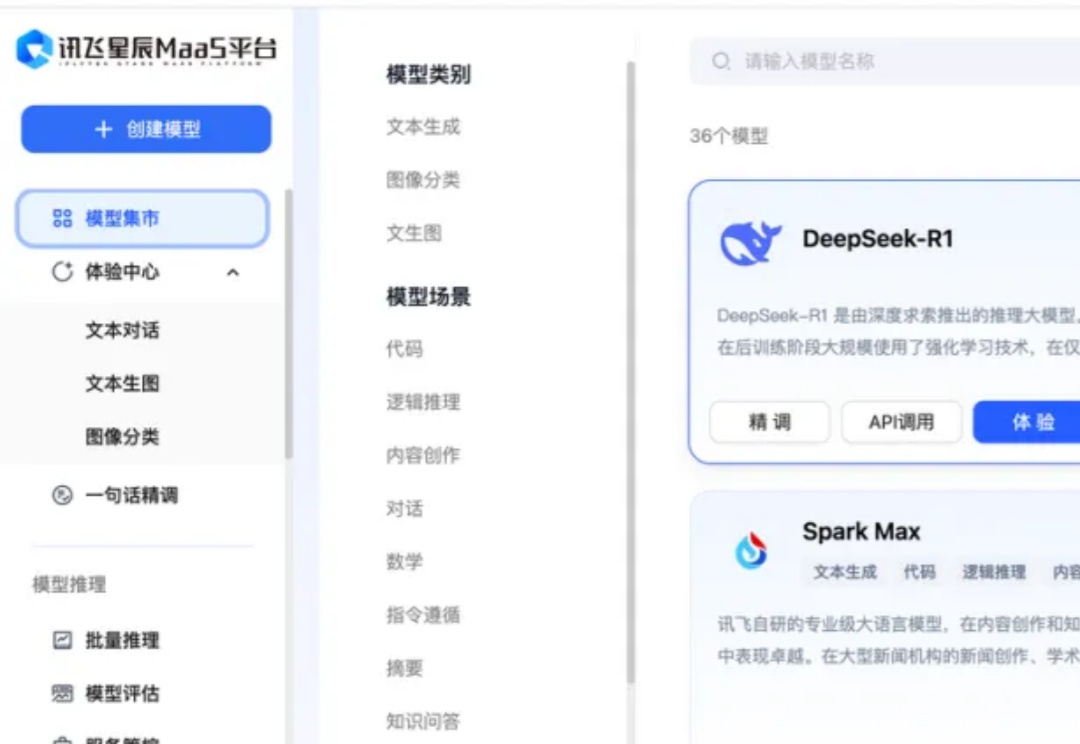
免费不限量!讯飞上线 DeepSeek 全家桶,还支持满血版精调,我爱了
免费不限量!讯飞上线 DeepSeek 全家桶,还支持满血版精调,我爱了整个春节假期,我眼睁睁看着 DeepSeek 从“全民狂欢”变成“全民卡顿”——官网十问九崩,还有谁没被“服务器正忙,请稍后重试”的提示,搞崩溃过。
来自主题: AI资讯
7294 点击 2025-02-13 09:33
 搜索
搜索
整个春节假期,我眼睁睁看着 DeepSeek 从“全民狂欢”变成“全民卡顿”——官网十问九崩,还有谁没被“服务器正忙,请稍后重试”的提示,搞崩溃过。

席卷全球的 DeepSeek 依然是科技圈最大的话题,连 San Altman 都承认每天醒来都会担忧。因此本周在巴黎举办的 AI 行动峰会聚光灯稍显黯淡,但这里依然汇聚了全球大量重要的头脑。

DeepSeek 最近的爆火程度令人咋舌。短短20天内用户量就突破3000万,导致官方服务器几乎天天处于过载状态。虽然市面上已经涌现出不少第三方接入平台,但这些平台大多针对个人用户,对开发者和企业的需求难以满足。
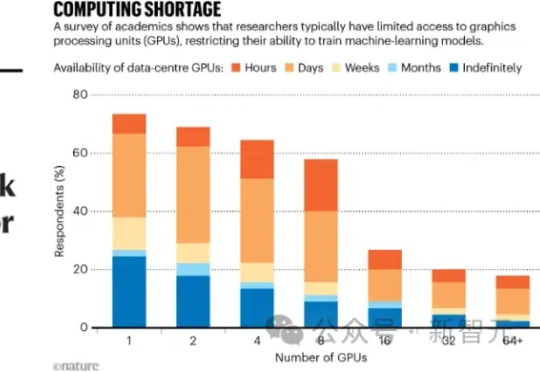
梁文峰说,钱从来都不是问题,唯一担心的是缺算力。不过,基于国产昇腾算力的DeepSeek R1系列推理API,性能已经直接对标高端GPU了!而且,华为已经率先携手国内15所头部高校,打造出了独一份的科教创新卓越/孵化中心,通过产教融合、科教融汇破解高校科研的算力困局。

推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。
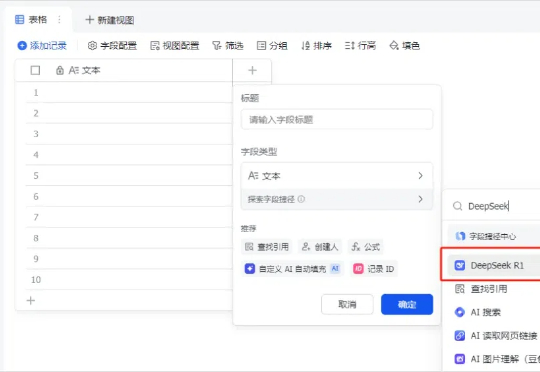
用了两天接入了DeepSeek R1的飞书,坦率的讲,我已经被彻底折服了,今天,我必须要写一篇文章安利一下。故事是这样的。飞书的多维表格,在前天下午接入了满血版的DeepSeek R1。

今天又得知咱们的老朋友,支付宝推出的智能体开发平台百宝箱,也悄悄接入了 DeepSeek!还一下子直接接入了 DeepSeek-R1 满血版、蒸馏版 32B、蒸馏版 7B、DeepSeek-V3 共四种尺寸。

还在为 DeepSeek R1 官网的卡顿抓狂?无问芯穹大模型服务平台现已上线满血版 DeepSeek-R1、V3,无需邀请即可免费用 Token!另有异构算力鼎力相助,支持通过 Infini-AI 异构云平台一键获取 DeepSeek 系列模型与多元异构自主算力服务。

DeepSeek 在海内外搅起的惊涛巨浪,余波仍在汹涌。当中国大模型撕开硅谷的防线之后,在预设中总是落后半拍的中国 AI 军团,这次竟完成了一次反向技术输出,引发了全球范围内复现 DeepSeek 的热潮。

近日,来自香港科技大学、南洋理工大学等机构的研究团队最新成果让这一设想成为现实。他们提出的 SelfDefend 框架,让大语言模型首次拥有了真正意义上的 ' 自卫能力 ',能够有效识别和抵御各类越狱攻击,同时保持极低的响应延迟。